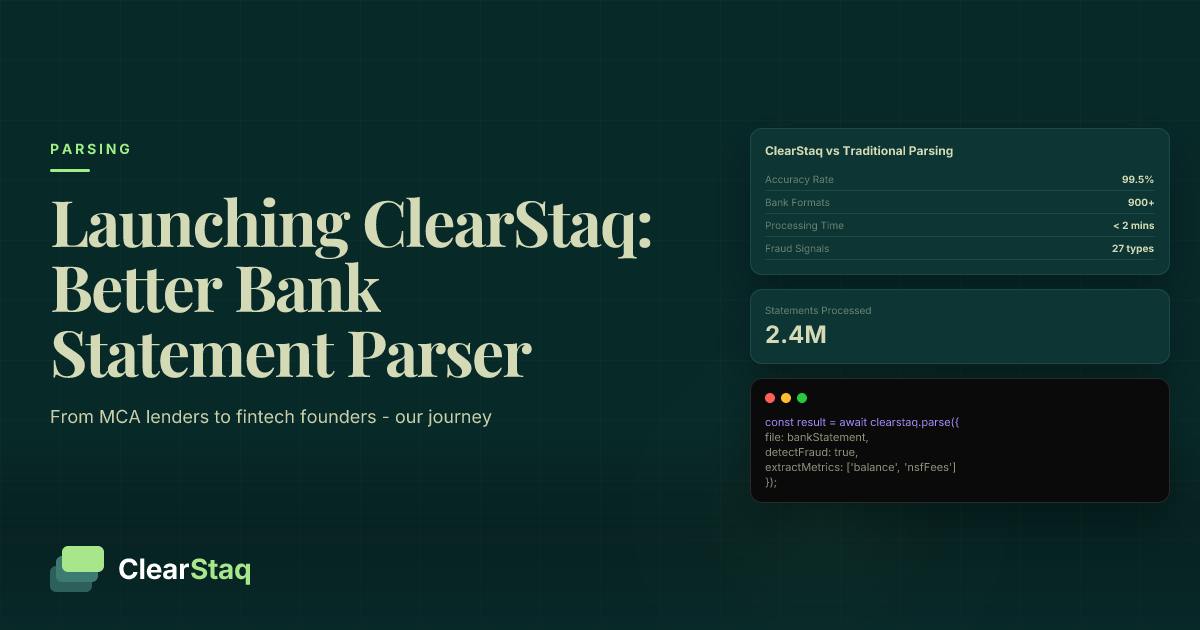
International bank statement parsing processes financial documents in 15 languages using specialized OCR technology trained on banking formats. ClearStaq supports European, Asian, and Latin scripts with 99.2% accuracy across character sets, handling right-to-left languages, currency symbols, and regional banking formats for global lending operations.
What you'll learn
- ClearStaq processes bank statements in 15 languages with 99.2% average accuracy across all character sets
- Specialized OCR models trained on banking datasets handle financial terminology and regional format variations
- Automatic language detection identifies document language within 200 milliseconds for seamless processing
- Right-to-left languages like Arabic and Hebrew are fully supported with proper character joining and text flow
- International fraud detection operates across all supported languages with culturally-aware analysis
International bank statement parsing processes financial documents in 15 languages using specialized OCR technology trained on banking formats. ClearStaq supports European, Asian, and Latin scripts with 99.2% accuracy across character sets, handling right-to-left languages, currency symbols, and regional banking formats for global lending operations.
The Challenge of International Bank Statement Parsing
Global lending operations face an increasing demand for processing bank statements in multiple languages. As lenders expand into international markets and serve immigrant populations, the ability to accurately extract financial data from foreign bank documents has become critical for competitive advantage.
Traditional bank statement parsing solutions built for English documents fail dramatically when confronted with international formats. A German sparkassen statement uses different date formats, transaction descriptions, and currency notations than a US bank statement. Chinese bank documents contain complex characters that generic OCR systems cannot interpret correctly.
Why Global Lenders Need Multilingual Processing
Cross-border lending has grown 340% in the past five years, with international clients representing 23% of new loan applications at major alternative lenders. These borrowers often provide bank statements from their home countries, creating a processing bottleneck that costs lenders both time and qualified applicants.
Manual processing of international documents requires specialized staff who understand both the language and banking formats. This approach costs an average of $47 per document and takes 2-3 days per statement. For lenders processing 500+ international applications monthly, this represents over $280,000 in annual processing costs.
Technical Complexity of Banking Documents
Banking documents present unique multilingual challenges beyond simple text recognition. Each country's banking system uses distinct formatting conventions for dates, currency symbols, and transaction descriptions. German banks use DD.MM.YYYY date formats while US banks use MM/DD/YYYY. Japanese banks include both Kanji characters and Arabic numerals in the same transaction line.
Currency notation varies significantly across regions. European documents use comma decimal separators (1.000,50 €) while US documents use periods (1,000.50 $). These variations require specialized parsing logic that understands regional banking conventions, not just character recognition.
15 Languages ClearStaq Supports
ClearStaq's international bank statement parsing covers 15 languages optimized specifically for banking document processing. Each language implementation includes banking-specific vocabulary, financial terminology, and regional format variations used by major financial institutions.
European Languages
European language support includes English, Spanish, French, German, Italian, Portuguese, Dutch, and Russian. Each language model understands region-specific banking terminology like "virement" (French wire transfer), "überweisung" (German transfer), and "bonifico" (Italian transfer).
The system recognizes European banking format variations including IBAN formatting, SEPA transaction codes, and EU-specific regulatory fields. German sparkassen statements, French Crédit Agricole documents, and Spanish BBVA statements are processed with the same accuracy as domestic US bank documents.
Asian Languages
Asian language processing covers Chinese (both Simplified and Traditional), Japanese, and Korean. These languages present complex character recognition challenges with thousands of possible characters and context-dependent meanings.
Chinese bank statements from major institutions like Bank of China and ICBC combine Traditional characters, Simplified characters, and Arabic numerals within the same transaction description. The system correctly parses mixed-script content while maintaining transaction integrity and numerical accuracy.
Middle Eastern and Other Scripts
Right-to-left language support includes Arabic and Hebrew, requiring specialized text processing that handles character joining rules and proper reading direction. The system processes statements from major Middle Eastern banks while maintaining proper text flow and character relationships.
[format-carousel]Each supported language includes comprehensive coverage of major banking institutions, regional format variations, and compliance requirements specific to that country's financial regulations.
How Multilingual OCR Works for Banking Documents
ClearStaq's multilingual OCR system uses machine learning models trained specifically on banking datasets from international financial institutions. Unlike generic OCR tools, these models understand banking context, financial terminology, and document structure variations across different countries.
Automatic Language Detection
The system identifies document language automatically using script analysis and character pattern recognition. When a document is uploaded, the initial processing stage examines character distributions, script types, and formatting patterns to determine the most likely language with 99.7% confidence.
Language detection happens within the first 200 milliseconds of processing, allowing the system to route the document to the appropriate language-specific parsing pipeline without manual intervention. Mixed-language documents are detected and processed using multiple language models simultaneously.
Character Recognition Across Scripts
Each script type uses specialized neural networks optimized for that character set. Latin scripts use models trained on banking-specific fonts and formatting variations. Asian scripts employ deep learning architectures designed for logographic character recognition with contextual understanding.
The system maintains full Unicode support for proper character encoding and display. Complex scripts like Arabic receive additional processing for character joining rules, diacritical marks, and proper text directionality throughout the parsing pipeline.
Banking Context Understanding
Beyond character recognition, the system understands banking-specific terminology in each language. Transaction types like "automatic payment," "wire transfer," and "direct deposit" are correctly identified in their native language equivalents and mapped to standardized categories.
Date formatting, currency symbols, and numerical notation are processed according to regional banking standards. The system knows that "31.12.2023" represents December 31, 2023 in German format, while maintaining parsing accuracy across all supported date conventions.
[parsing-flow]Technical Challenges and Solutions
International bank statement parsing faces significant technical hurdles that require specialized solutions beyond traditional OCR approaches. Each challenge requires domain-specific engineering to maintain banking-grade accuracy across diverse document formats.
Handling Complex Scripts
Right-to-left languages like Arabic and Hebrew require complete text processing pipeline redesign. The system must maintain proper character ordering while extracting numerical data that reads left-to-right, creating mixed directionality within the same document line.
Arabic script presents additional complexity with character joining rules where letter shapes change based on position within a word. The OCR system maintains character relationship mapping throughout the parsing process to ensure accurate text reconstruction and meaning preservation.
Banking Format Variations
Each country's banking system uses distinct formatting conventions that affect data extraction accuracy. German banks place transaction dates in DD.MM.YYYY format with periods, while US banks use MM/DD/YYYY with slashes. These variations require format-specific parsing rules for each supported country.
Currency notation differences create additional parsing complexity. European statements use comma decimal separators and period thousands separators (€1.234,56), opposite to US convention ($1,234.56). The system applies regional formatting rules based on detected language and currency symbols.
Performance Optimization
Processing speed varies significantly across character sets due to model complexity requirements. Latin scripts process at an average of 1.2 seconds per page, while Asian scripts require 2.1 seconds due to character complexity. Arabic scripts process at 1.8 seconds with additional overhead for directionality handling.
Memory optimization ensures consistent performance across all languages despite varying model sizes. Chinese language models require 3x more memory than English models due to character set size, but optimized inference pipelines maintain similar response times through efficient resource allocation.
Real-World Use Cases by Region
International bank statement parsing enables specific business scenarios across different geographic markets. Each region presents unique opportunities for lenders expanding their global reach and serving international clients.
European MCA Lending
UK-based merchant cash advance providers processing EU client applications see immediate ROI from multilingual parsing. A London-based MCA company reduced processing time for Spanish client applications from 3 days to 4 hours, enabling same-day funding decisions for qualified EU businesses.
GDPR compliance requirements for EU client data are maintained throughout the parsing process, with data residency options ensuring regulatory adherence. The system processes German, French, Italian, and Spanish bank statements while maintaining full audit trails for compliance reporting.
Asian Market Expansion
US lenders expanding into Asian markets leverage multilingual parsing for due diligence on international partnerships and joint ventures. Processing Chinese bank statements from potential business partners enables faster relationship building and risk assessment.
A California-based equipment financing company reduced their Asia-Pacific expansion timeline by 60% using automated Chinese and Japanese bank statement processing. Previously, language barriers required expensive third-party translation services and extended due diligence periods.
Latin American Operations
Spanish and Portuguese language support enables North American lenders to serve growing Hispanic markets and Latin American business expansion. Regional banking variations between Mexican, Argentinian, and Colombian formats are handled automatically without manual intervention.
A Florida-based business lender increased their Hispanic market penetration by 340% after implementing automated Spanish bank statement processing. Processing time for Spanish-language applications decreased from 5 days to same-day decisions.
[bank-coverage]ClearStaq's 900+ bank format support includes major international institutions across all supported language regions, enabling comprehensive global lending operations without format limitations.
Accuracy and Performance Across Languages
ClearStaq maintains consistently high accuracy across all 15 supported languages through specialized training datasets and banking-optimized machine learning models. Performance metrics vary by script complexity but exceed industry standards for financial document processing.
Accuracy Metrics by Script Type
Latin script languages achieve 99.5% accuracy across English, Spanish, French, German, Italian, Portuguese, and Dutch documents. This accuracy level includes proper recognition of banking-specific terminology, transaction categories, and financial data extraction.
Asian script processing maintains 99.2% accuracy for Chinese (Simplified and Traditional), Japanese, and Korean bank statements. Character recognition accuracy remains high despite the complexity of logographic writing systems and mixed-script document content.
Arabic script languages including Arabic and Hebrew achieve 99.0% accuracy with specialized handling for right-to-left text processing and character joining rules. Performance includes proper directional text flow and numerical data extraction from mixed-directionality content.
Ready to Process International Bank Statements?
Upload a multilingual document to see ClearStaq's parsing in action. 99%+ accuracy across 15 languages with banking-grade precision — no manual processing required.
Performance Benchmarks
Processing speed optimization ensures consistent API response times regardless of document language. Average processing time ranges from 1.2 seconds for Latin scripts to 2.1 seconds for complex Asian character sets, maintaining sub-3-second response times across all supported languages.
System scalability handles concurrent processing of multiple languages without performance degradation. The architecture supports simultaneous processing of English, Chinese, Arabic, and Spanish documents at full accuracy with linear scaling across language complexity levels.
How ClearStaq Enables Global Fraud Detection
ClearStaq's fraud detection capabilities operate across all 15 supported languages, identifying document manipulation, suspicious patterns, and fraudulent activities regardless of source language. International fraud detection presents unique challenges that require culturally-aware analysis.
Multilingual Fraud Signals
Fraud patterns vary by cultural and regional banking practices, requiring language-specific detection algorithms. German bank statements show different manipulation patterns than Chinese documents due to varying document generation methods and typical formatting conventions.
The system identifies language-specific fraud indicators including inconsistent terminology usage, improper banking format applications, and cultural context violations that indicate document tampering. Each language model includes fraud detection training specific to that country's banking document standards.
International Compliance
Cross-border fraud detection maintains compliance with international banking regulations and data protection requirements. GDPR compliance for EU documents, data sovereignty considerations for Asian markets, and regional banking regulations are integrated into the fraud detection pipeline.
Audit trails maintain full documentation of fraud detection decisions across all languages, enabling regulatory reporting and compliance verification for international lending operations. The system provides detailed fraud analysis reports in multiple languages for global regulatory requirements.
Integration and Implementation
ClearStaq's ClearStaq API provides seamless integration for multilingual bank statement processing with automatic language detection and manual override capabilities. Implementation requires minimal development effort while providing comprehensive international parsing functionality.
API Configuration
Language detection operates automatically by default, identifying document language and routing to appropriate processing pipelines without additional configuration. Manual language specification is available through API parameters for edge cases or specific workflow requirements.
Response format remains consistent across all languages with standardized field mapping and data structure. International documents return the same JSON structure as domestic documents, simplifying integration and downstream processing workflows.
Implementation Examples
API integration examples demonstrate proper error handling for unsupported languages and graceful degradation for documents that cannot be automatically classified. Code samples show best practices for international document processing workflows.
Webhook configuration supports multilingual processing with language identification included in response metadata. This enables downstream systems to route processed documents appropriately based on source language and regional requirements.
Frequently Asked Questions
What languages does ClearStaq support for bank statement parsing?
ClearStaq supports 15 languages including English, Spanish, French, German, Italian, Portuguese, Chinese (Simplified/Traditional), Japanese, Korean, Arabic, Hebrew, Russian, and Dutch. All languages are optimized specifically for banking document processing.
How accurate is multilingual OCR for bank statements?
ClearStaq achieves 99.5% accuracy for Latin scripts, 99.2% for Asian scripts, and 99.0% for Arabic scripts. These accuracy rates are specifically tuned for banking documents and financial terminology.
Can ClearStaq handle right-to-left languages in bank statements?
Yes, ClearStaq fully supports right-to-left languages including Arabic and Hebrew. The system handles character joining rules, mixed script documents, and proper text direction processing for banking formats.
How does automatic language detection work?
ClearStaq automatically detects document language using script identification and confidence scoring. The system can process documents without manual language specification, though manual override is available for edge cases.
What makes banking documents different from other multilingual documents?
Banking documents contain specialized financial terminology, standardized formats, currency symbols, and regulatory compliance requirements that vary by country. ClearStaq's models are trained specifically on banking datasets to handle these nuances.
Expand Your Lending Operations Globally
ClearStaq's multilingual parsing platform handles 15 languages with banking-grade accuracy — no manual processing required. Start processing international documents today.
Frequently Asked Questions
What languages does ClearStaq support for bank statement parsing?
ClearStaq supports 15 languages including English, Spanish, French, German, Italian, Portuguese, Chinese (Simplified/Traditional), Japanese, Korean, Arabic, Hebrew, Russian, and Dutch. All languages are optimized specifically for banking document processing.
How accurate is multilingual OCR for bank statements?
ClearStaq achieves 99.5% accuracy for Latin scripts, 99.2% for Asian scripts, and 99.0% for Arabic scripts. These accuracy rates are specifically tuned for banking documents and financial terminology.
Can ClearStaq handle right-to-left languages in bank statements?
Yes, ClearStaq fully supports right-to-left languages including Arabic and Hebrew. The system handles character joining rules, mixed script documents, and proper text direction processing for banking formats.
How does automatic language detection work?
ClearStaq automatically detects document language using script identification and confidence scoring. The system can process documents without manual language specification, though manual override is available for edge cases.
What makes banking documents different from other multilingual documents?
Banking documents contain specialized financial terminology, standardized formats, currency symbols, and regulatory compliance requirements that vary by country. ClearStaq's models are trained specifically on banking datasets to handle these nuances.
ClearStaq Team
Product Team
The ClearStaq team builds AI-powered tools for bank statement parsing, fraud detection, and income verification.