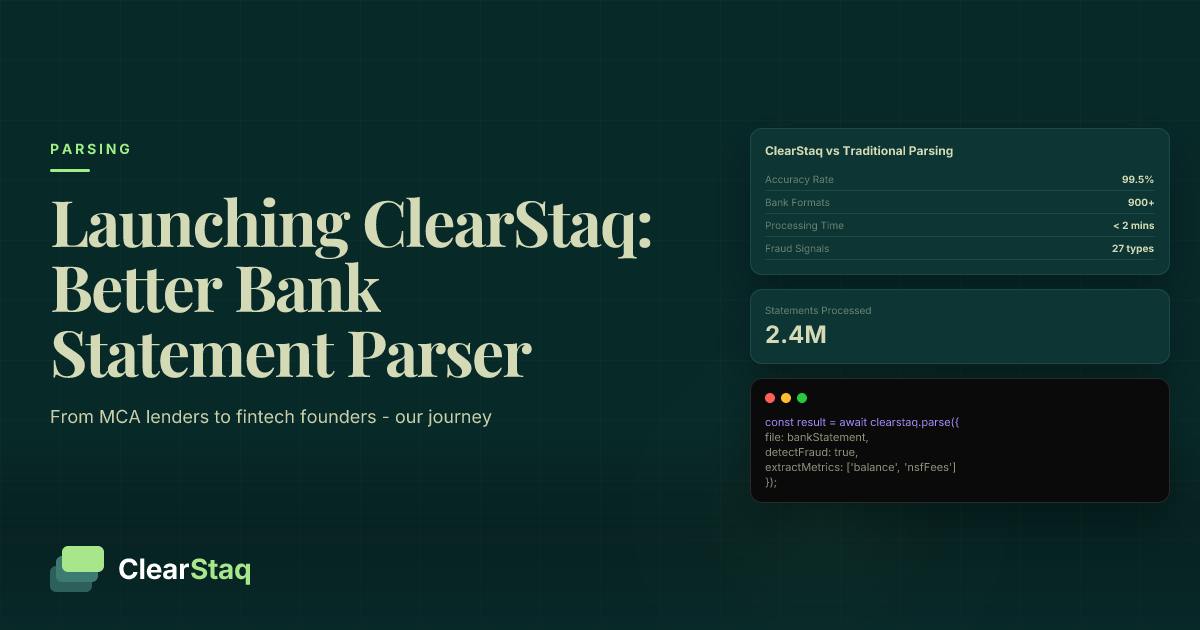
Bank statement parsing accuracy of 99.5% represents industry-leading precision where fewer than 1 in 200 data points contain errors. This benchmark matters because a 0.5% improvement can prevent thousands in loan losses, reduce manual review time by 80%, and ensure regulatory compliance for financial institutions processing high-volume applications.
What you'll learn
- 99.5% parsing accuracy reduces errors from 5% to 0.5%, eliminating most manual review requirements
- A 0.5% accuracy improvement can prevent thousands in loan losses and reduce review time by 80%
- AI-powered parsing achieves 98-99.5% accuracy versus 85-92% for traditional OCR systems
- Field-level accuracy matters more than character-level for financial lending decisions
- Real-time quality monitoring maintains consistent 99.5% accuracy across 900+ bank formats
Bank statement parsing accuracy of 99.5% represents industry-leading precision where fewer than 1 in 200 data points contain errors. This benchmark matters because a 0.5% improvement can prevent thousands in loan losses, reduce manual review time by 80%, and ensure regulatory compliance for financial institutions processing high-volume applications.
What Is Bank Statement Parsing Accuracy?
Bank statement parsing accuracy measures the percentage of correctly extracted data points from financial documents. Unlike general document OCR, which might tolerate minor errors, bank statement parsing demands precision for every transaction amount, date, description, and balance.
Think of it this way: a single misread digit in a transaction amount could mean the difference between loan approval and rejection. That's why financial institutions can't settle for the 85-92% accuracy rates typical of traditional OCR systems.
Types of Parsing Accuracy Metrics
Character-level accuracy counts individual characters correctly identified. While useful for general OCR benchmarking, it doesn't capture the full picture for financial documents. A 99% character accuracy might still mean every transaction amount has errors if decimal points are consistently misplaced.
Field-level accuracy measures complete data fields extracted correctly. For bank statements, this includes transaction amounts, dates, merchant names, and running balances. This metric matters most for lenders because you need the entire field correct, not just most characters.
Document-level accuracy tracks the percentage of statements processed without any errors. At 99.5% field-level accuracy, you might achieve 95% document-level accuracy for statements with 100+ transactions. This shows why even small accuracy improvements have massive operational impact.
How Bank Statements Differ from Other Documents
Bank statements present unique parsing challenges compared to invoices or receipts. They contain structured financial data with strict mathematical relationships — running balances must reconcile with transactions, dates must follow chronological order, and formats vary widely across 900+ financial institutions.
Regulatory compliance adds another layer of complexity. The Federal Reserve and FDIC require accurate documentation for lending decisions. A parsing error isn't just an inconvenience; it's a compliance risk that could trigger audits or penalties.
The high-stakes nature of lending decisions means accuracy directly impacts business outcomes. A missed deposit could underqualify a borrower, while an undetected fraudulent transaction could lead to loan losses. Every data point matters.
Why 99.5% Accuracy Is the Industry Gold Standard
The jump from 95% to 99.5% accuracy might seem incremental, but it transforms operational efficiency. At 95% accuracy, you're reviewing errors on every statement. At 99.5%, manual review becomes the exception, not the rule.
Regulatory Standards for Financial Document Processing
Federal Reserve guidelines emphasize the importance of accurate financial documentation in credit decisions. While they don't mandate specific accuracy percentages, they require lenders to demonstrate reliable processes for verifying borrower information.
FDIC examination procedures specifically review document verification processes. Institutions using automated parsing must show their systems maintain accuracy levels that support sound lending decisions. Industry best practices have converged on 99%+ accuracy as the minimum threshold for automated processing.
Financial institutions face increasing scrutiny around fair lending practices. Parsing errors that systematically disadvantage certain borrower segments could trigger compliance violations. High accuracy ensures equitable treatment across all applications.
Competitive Landscape of Parsing Accuracy
The parsing accuracy landscape reveals a clear technology hierarchy. Traditional OCR systems achieve 85-92% accuracy on bank statements, requiring substantial manual review. These systems struggle with format variations and can't adapt to new layouts without manual template updates.
Template-based parsing systems perform better at 93-97% accuracy. They work well for known formats but fail when encountering new bank layouts or non-standard statements. Maintaining template libraries becomes a constant operational burden.
AI-powered solutions like ClearStaq achieve 98-99.5% accuracy by understanding document context rather than relying on rigid templates. Machine learning models adapt to format variations and improve continuously with new data.
As the visualization shows, each percentage point of accuracy improvement dramatically reduces error rates and manual review requirements. The difference between 97% and 99.5% accuracy means 5x fewer errors to review.
The Hidden Costs of Parsing Inaccuracy
Parsing errors create cascading costs throughout the lending process. What starts as a simple data extraction mistake compounds into operational inefficiencies, increased risk, and degraded customer experience.
Manual Review and Labor Costs
At 95% accuracy, underwriters spend 30-45 minutes reviewing each application for parsing errors. With experienced underwriters earning $35-50 per hour, manual review adds $17-37 per application in labor costs alone.
For a lender processing 1,000 applications monthly, improving from 95% to 99.5% accuracy saves 450 hours of manual review time. That's nearly three full-time employees freed up for higher-value analysis rather than error correction.
Scaling becomes impossible without high accuracy. As application volume grows, manual review requirements grow linearly. Lenders hit a ceiling where they can't hire reviewers fast enough to maintain service levels.
Loan Loss Prevention
Parsing errors directly impact credit decisions. A missed NSF fee might hide cash flow problems. An overlooked deposit could be fraudulent. These errors slip through to become loan losses months later.
For MCA underwriting, where decisions rely heavily on cash flow analysis, a 0.5% error rate on transaction data can translate to 2-3% higher default rates. On a $10 million portfolio, that's $200,000-300,000 in preventable losses.
Fraud detection depends on accurate data extraction. If your parser misses suspicious transaction patterns or irregular deposits, your fraud models can't protect you. Every parsing error is a potential blind spot for risk assessment.
Compliance and Regulatory Risk
Regulatory examinations scrutinize documentation accuracy. Systemic parsing errors suggest weak controls and can trigger enforcement actions. One financial institution faced $1.2 million in penalties after examiners found their automated system consistently misread deposit amounts.
Audit trails require accurate source data. If your parsing introduces errors, you can't prove your lending decisions were based on accurate information. This documentation gap creates liability in fair lending reviews.
Customer complaints about incorrect decisions often trace back to parsing errors. These complaints trigger regulatory scrutiny and damage institutional reputation. High accuracy prevents these issues at the source.
4 Factors That Impact Parsing Accuracy
Understanding what drives parsing accuracy helps you optimize your document processing pipeline. These four factors determine whether you achieve 85% or 99.5% accuracy.
Document Quality and Image Resolution
Image quality forms the foundation of accurate parsing. Documents scanned at less than 200 DPI lose critical detail, especially for small transaction text. Mobile phone captures add complexity with varying lighting and angles.
PDF generation method matters more than most realize. Native PDFs from bank portals contain searchable text layers, enabling near-perfect extraction. Scanned PDFs require OCR processing, introducing potential errors. Screenshots and photos perform worst, often dropping accuracy below 90%.
Pre-processing can salvage poor-quality documents. Image enhancement, deskewing, and contrast adjustment recover 5-10% accuracy on challenging inputs. But starting with high-quality sources remains the best strategy.
Bank Format Variations
With over 900 unique bank statement formats in circulation, format variation creates the biggest parsing challenge. Each bank uses different layouts, fonts, and data organization. Regional banks often change formats quarterly, breaking template-based systems.
Major banks like Chase, Wells Fargo, and Bank of America maintain relatively stable formats, achieving 99.7%+ parsing accuracy. Regional banks and credit unions present more challenges, with some formats dropping to 97-98% accuracy even with advanced AI.
Automatic format detection
No configuration required • Just upload and go
International formats add complexity with different date formats (DD/MM vs MM/DD), decimal separators (periods vs commas), and currency symbols. A parser trained only on US formats will fail catastrophically on international statements.
AI/ML vs Traditional OCR Performance
Traditional OCR treats bank statements as images, recognizing characters without understanding context. It can't distinguish between a balance and a transaction amount, leading to field-level errors even with perfect character recognition.
Template-based systems improve on pure OCR by understanding document structure. They map specific regions to data fields, achieving higher accuracy on known formats. But they break immediately when formats change, requiring constant maintenance.
AI and machine learning models understand both visual and semantic patterns. They recognize that balances follow transactions, dates appear in sequence, and amounts have decimal points. This contextual understanding drives the leap from 95% to 99.5% accuracy.
How We Measure Accuracy at ClearStaq
Accuracy claims mean nothing without rigorous measurement. ClearStaq maintains complete transparency in how we calculate and report our 99.5% accuracy rate.
Ground Truth Creation Process
Every accuracy measurement starts with ground truth — human-verified correct answers for each data field. Our validation team manually reviews thousands of bank statements, extracting every transaction, balance, and date to create reference datasets.
We use consensus methodology where three validators independently extract data from each statement. Only when all three agree do we consider a field verified. Disagreements go to senior validators for resolution. This process ensures our ground truth is actually true.
Quality control samples 10% of validated statements for re-review by different validators. This catches any systematic errors in our ground truth creation and maintains baseline accuracy above 99.9%.
Automated Accuracy Testing
Our automated testing framework runs continuously, processing thousands of statements daily against verified ground truth. Every parsing result gets compared field-by-field, flagging any discrepancies for analysis.
A/B testing lets us evaluate model improvements safely. New models process statements in parallel with production models, comparing accuracy before deployment. Only improvements that maintain or exceed 99.5% accuracy across all formats move to production.
Real-time monitoring tracks accuracy by bank format, document type, and quality score. If accuracy drops below 99.5% for any segment, alerts trigger immediate investigation. This proactive approach maintains consistent performance.
Field-Level Accuracy Reporting
We report accuracy at the field level because that's what matters for lending decisions. Character-level metrics can hide critical errors — 99% character accuracy means nothing if every transaction amount has a misplaced decimal.
Transaction-level precision tracks complete extraction accuracy for date, description, amount, and balance fields together. A transaction is only correct if all fields match ground truth exactly. This strict standard ensures reliable data for credit analysis.
Our ClearStaq API returns confidence scores for each extracted field, letting you implement additional validation for critical data points. This transparency helps you build robust workflows around our parsing engine.
Our 5-Step Process to Achieve 99.5% Accuracy
Achieving 99.5% accuracy requires more than good OCR. Our five-step process combines advanced AI with rigorous quality control to deliver consistent results across all bank statement parsing platform features.
Document Preprocessing Pipeline
Step 1 begins before parsing even starts. Our preprocessing pipeline enhances document quality, standardizes formats, and scores readability. Images get deskewed, contrast-adjusted, and sharpened. PDFs are analyzed for text layers and optimized for extraction.
Format standardization converts various input types into a consistent processing format. Whether you submit native PDFs, scanned images, or mobile photos, our pipeline normalizes them for optimal parsing accuracy.
Quality scoring predicts parsing difficulty before processing begins. Low-quality documents get additional enhancement passes. Documents scoring below minimum thresholds return warning messages, letting you request better source files rather than accepting poor results.
AI Model Architecture
Step 2 deploys our multi-model AI architecture. Rather than relying on a single model, we use specialized models for different parsing tasks. Layout analysis models identify statement structure. OCR models extract text. Classification models determine field types.
Ensemble methods combine predictions from multiple models, using confidence-weighted voting to select final values. If models disagree significantly, the system flags fields for additional validation rather than guessing.
Our models train on millions of real bank statements, learning patterns across formats and institutions. Unlike template systems, they adapt to new formats automatically, maintaining accuracy even as banks update their layouts.
Validation and Quality Assurance
Steps 3-5 focus on validation and continuous improvement. Mathematical validation checks that running balances reconcile with transactions. Date validation ensures chronological consistency. Format validation confirms amounts follow expected patterns.
Cross-validation compares extracted data against known patterns for each bank. If Chase statements suddenly show different field arrangements, the system flags potential format changes for review.
Error detection algorithms identify likely mistakes before they reach your application. Suspicious patterns like duplicate transactions, impossible dates, or mismatched balances trigger additional validation passes.
Accuracy Across 900+ Bank Formats
Maintaining 99.5% accuracy across 900+ formats requires deep understanding of banking ecosystem diversity. Each format presents unique challenges that our system addresses specifically.
Major Bank Format Performance
Major banks like Chase, Wells Fargo, and Bank of America achieve our highest accuracy rates at 99.7%+. Their standardized formats, consistent layouts, and high-volume usage provide extensive training data for our models.
These banks benefit from stable format evolution. When they update layouts, changes roll out gradually across regions, giving our models time to adapt. Their digital-first approach also means most statements are native PDFs with perfect text layers.
High-volume processing for major banks enables rapid model improvement. With thousands of daily statements, our system quickly identifies and corrects any accuracy degradation, maintaining peak performance.
Regional and Credit Union Challenges
Regional banks and credit unions present unique challenges. Lower transaction volumes mean less training data. Frequent format changes break template-based approaches. Some still use legacy systems producing lower-quality PDFs.
We maintain 98.5-99.5% accuracy even on challenging regional formats through transfer learning. Models trained on major bank formats adapt to regional variations, requiring less format-specific training data.
Custom validation rules for regional institutions catch format-specific quirks. Some credit unions use non-standard date formats or unique transaction codes that require specialized handling to maintain accuracy.
International Format Support
International bank statements add layers of complexity. Currency symbols vary by country. Date formats switch between DD/MM/YYYY and MM/DD/YYYY. Decimal separators use periods or commas depending on region.
Language variations require multilingual models. While transaction amounts are universal, merchant names and transaction descriptions appear in local languages. Our models handle 15 major languages while maintaining 99%+ accuracy.
Every major US bank, credit union, and fintech
Automatic format detection • Zero configuration required
The visualization shows our current coverage across financial institutions. Green indicates 99.5%+ accuracy, yellow shows 98-99.5%, and new formats under development appear in gray. We continuously expand coverage based on customer demand.
Quality Assurance and Continuous Improvement
Achieving 99.5% accuracy is just the beginning. Maintaining that accuracy as formats evolve and new banks emerge requires constant vigilance and improvement.
Real-Time Quality Monitoring
Our monitoring dashboards track accuracy metrics in real-time across every dimension — by bank, format type, document quality, and time period. Any degradation triggers immediate alerts to our engineering team.
Alert thresholds vary by metric importance. A 0.1% drop in transaction amount accuracy triggers immediate investigation. Description accuracy can vary more without impacting lending decisions. This prioritized approach focuses resources where they matter most.
Performance tracking extends beyond accuracy to processing speed and API reliability. We maintain 99.99% uptime with sub-second parsing for most documents. Accuracy means nothing if the service isn't available when you need it.
Model Updates and Improvement Cycles
Weekly model updates incorporate new training data and format variations. Our continuous learning pipeline automatically identifies patterns in parsing errors and adjusts models to prevent recurrence.
New data integration follows strict validation protocols. Customer-submitted statements expand our training corpus, but only after anonymization and quality verification. This real-world data keeps our models current with evolving formats.
Performance optimization balances accuracy with speed. Some accuracy improvements require more processing time. We carefully evaluate tradeoffs, prioritizing accuracy for financial data while maintaining practical processing speeds.
Customer Feedback Loop
Your feedback drives our improvement priorities. Error reporting through our API helps identify edge cases our testing might miss. Format requests for new banks guide our expansion roadmap.
We validate reported errors within 24 hours and deploy fixes within a week for critical issues. This rapid response maintains trust and ensures your operations aren't disrupted by parsing problems.
Accuracy validation happens transparently. Unlike black-box solutions, we share detailed accuracy metrics and invite customers to validate our claims with their own data. This openness builds confidence in our fraud detection accuracy and overall platform reliability.
Frequently Asked Questions
What is considered good accuracy for bank statement parsing?
Industry-leading accuracy is 99.5%, while traditional OCR achieves 85-92% and template-based systems reach 93-97%. For financial documents, anything below 98% requires significant manual review.
How is bank statement parsing accuracy measured?
Accuracy is measured at the field level by comparing extracted data points against human-validated ground truth. This includes transaction amounts, dates, descriptions, and running balances across the entire document.
What factors affect bank statement parsing accuracy?
Four main factors impact accuracy: document quality (resolution, scan clarity), format complexity (layout variations), data density (transaction volume), and technology approach (OCR vs AI/ML models).
Why does 99.5% accuracy matter for lenders?
A 0.5% accuracy improvement can prevent thousands in loan losses, reduce manual review time by 80%, and ensure regulatory compliance. For high-volume lenders, this translates to significant operational savings.
How does AI improve parsing accuracy over traditional OCR?
AI models understand context and relationships between data points, adapt to format variations, and learn from errors. Traditional OCR relies on character recognition alone, while AI considers document structure and financial logic.
Experience 99.5% Accuracy Firsthand
Upload a bank statement to our API and see field-level accuracy reporting in real-time. Start your free trial — no credit card required.
Stop Settling for 95% Accuracy
When 99.5% accuracy is possible, why accept anything less? Test ClearStaq's parsing engine and see the difference precision makes for your lending operations. Start your free trial today.
Frequently Asked Questions
What is considered good accuracy for bank statement parsing?
Industry-leading accuracy is 99.5%, while traditional OCR achieves 85-92% and template-based systems reach 93-97%. For financial documents, anything below 98% requires significant manual review.
How is bank statement parsing accuracy measured?
Accuracy is measured at the field level by comparing extracted data points against human-validated ground truth. This includes transaction amounts, dates, descriptions, and running balances across the entire document.
What factors affect bank statement parsing accuracy?
Four main factors impact accuracy: document quality (resolution, scan clarity), format complexity (layout variations), data density (transaction volume), and technology approach (OCR vs AI/ML models).
Why does 99.5% accuracy matter for lenders?
A 0.5% accuracy improvement can prevent thousands in loan losses, reduce manual review time by 80%, and ensure regulatory compliance. For high-volume lenders, this translates to significant operational savings.
How does AI improve parsing accuracy over traditional OCR?
AI models understand context and relationships between data points, adapt to format variations, and learn from errors. Traditional OCR relies on character recognition alone, while AI considers document structure and financial logic.
ClearStaq Team
Product Team
The ClearStaq team builds AI-powered tools for bank statement parsing, fraud detection, and income verification.